拒绝采样(reject sampling)的简单认识
13 Jul 2013
从下午两点开始,我开始联网,到了三点半才连上,国家图书馆的网子伤不起啊。刚开始在三楼连,然后又跑到一楼连,眼巴巴地开着人家呼呼地刷网页,我真替我的本子着急,不能给点力啊。总觉得信号不好,本子与那些苹果们在一些也许受欺负了。果断来到了二楼,嘿连上了,嗨!
闲言少叙,言归正传。拒绝采样是蒙特卡罗方法的一种,在众多的采样方法中,这种方法显得独树一帜。而且,这种方法与Metropolis-Hastings算法也有一定关系。接下来,介绍一下这种方法的道理所在,注意,只是讲道理,许多细节并不规范,所以各位看官也不要太苛刻啊。
下图是一个随机变量的密度函数曲线,试问如何获得这个随机变量的样本呢?
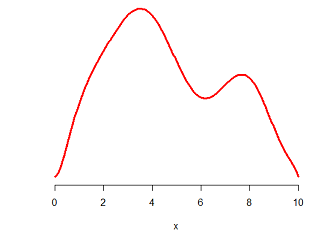
利用这个曲线的形状来抽取样本,用一个矩形将这个密度曲线套起来,把密度曲线框在一个矩形里,如下:
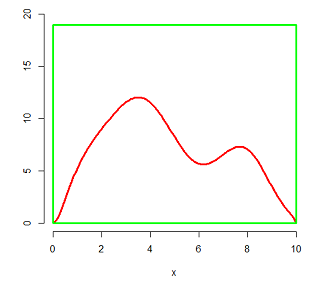
然后,向这个矩形里随机投点。随机投点意味着在矩形这块区域内,这些点是满足均匀分布的。投了大概10000个点,如下面这个样子:
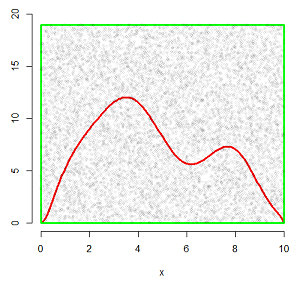
显然,有的点落在了密度曲线下侧,有的点落在了密度曲线的上侧。上侧的点用绿色来表示,下侧的点用蓝色来表示,如下图:
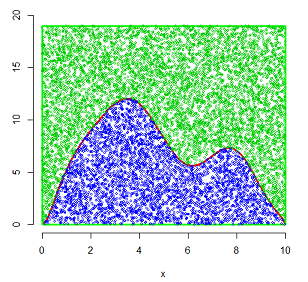
只保留密度曲线下侧的点,即蓝色的点:
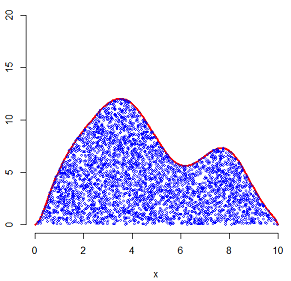
到这里,提一个问题,在密度曲线以下的这块区域里,这些点满足什么分布?均匀分布!这是拒绝采样最关键的部分,搞个矩形、向矩形里投点等等,所做的一切都是为了获得一个密度曲线所围成区域的均匀分布。只要能获得这样一个在密度曲线下满足均匀分布的样本,我们就可以获得与该密度曲线相匹配的随机变量的采样样本。方法是,只需把每个蓝点的横坐标提取出来,这些横坐标所构成的样本就是我们的目标样本。下图左侧,是按照以上方法获得的一个样本的直方图以及核密度估计,下图右侧,是开始的密度曲线。
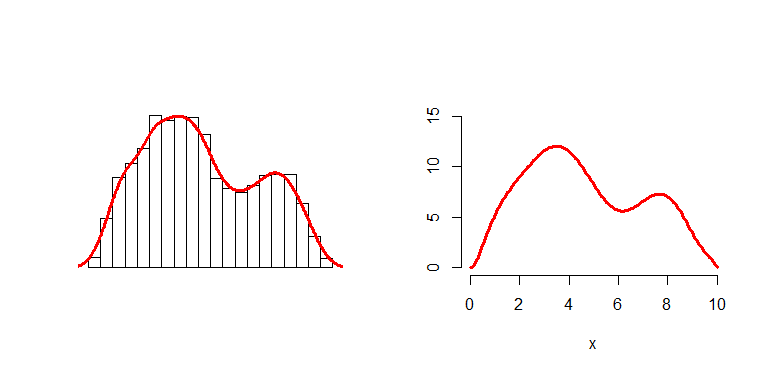
可见,采样样本的核密度估计与目标密度曲线基本一致,可以肯定这个样本就是目标样本。
最开始时候用到了一个矩形,这个矩形就是一个满足均匀分布的建议分布,建议分布只是获得目标密度函数曲线下均匀分布样本的一个辅助工具。采用均匀分布作为建议分布有时效率很低,为什么这么说?从上例就可以看出,均匀分布的好多点(那些绿点)都被剔除了,造成了一种浪费。可以选择一些其他曲线来把密度曲线框起来,效率会提高一点,如下图:
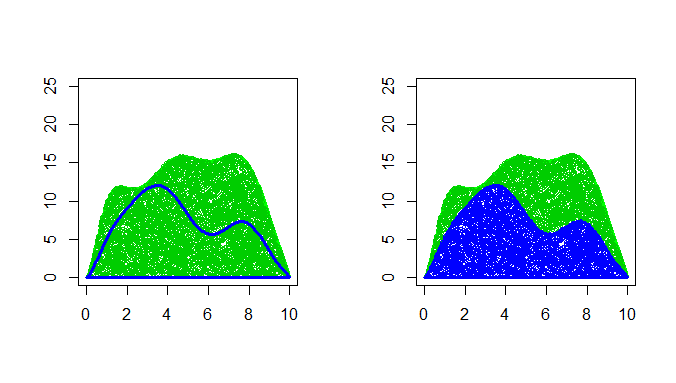
这里目标密度函数曲线为h(x), 对应于下图中的蓝线,建议分布密度曲线为g(x),我们把g(x)乘上一个常数因子c,然后用cg(x)这条曲线将目标密度曲线框起来。
我们假定满足g(x)的随机变量易于采样,那么拒绝采样的步骤如下:
- 从g(x)采到一个样本数据,记为$x^{\star}$,我们把它作为一个建议
- 要不要接受这个建议,作为满足h(x)分布的一个样本数据呢?我们定义一个接受概率:
也就是说,我们以$\alpha$的概率接受$x^{\star}$作为h(x)分布的一个样本数据。实际操作中,我们是取一个$U(0, 1)$的随机数$\mu$,如果$\mu<\alpha$,就接受$x^{\star}$作为h(x)的一个样本数据,否则,把它舍弃掉,回到1步继续循环。最终可以获得一个样本。
- 文章开头是一下子抽取10000个点,到后来怎么成了一个个抽了呢?其实它们是对应的,把蓝点去掉的过程就相当于你做是否拒绝判断的过程。
- 如果有密度曲线下的均匀分布样本,就可以得到与密度曲线相匹配的分布的一个样本。
- 如果建议分布的形状和目标分布越接近,采样的效率就越高。
Reference:
- 北京大学统计科学中心暑期课程–Monte Carlo方法(Rong Chen)
- Rejection Sampling